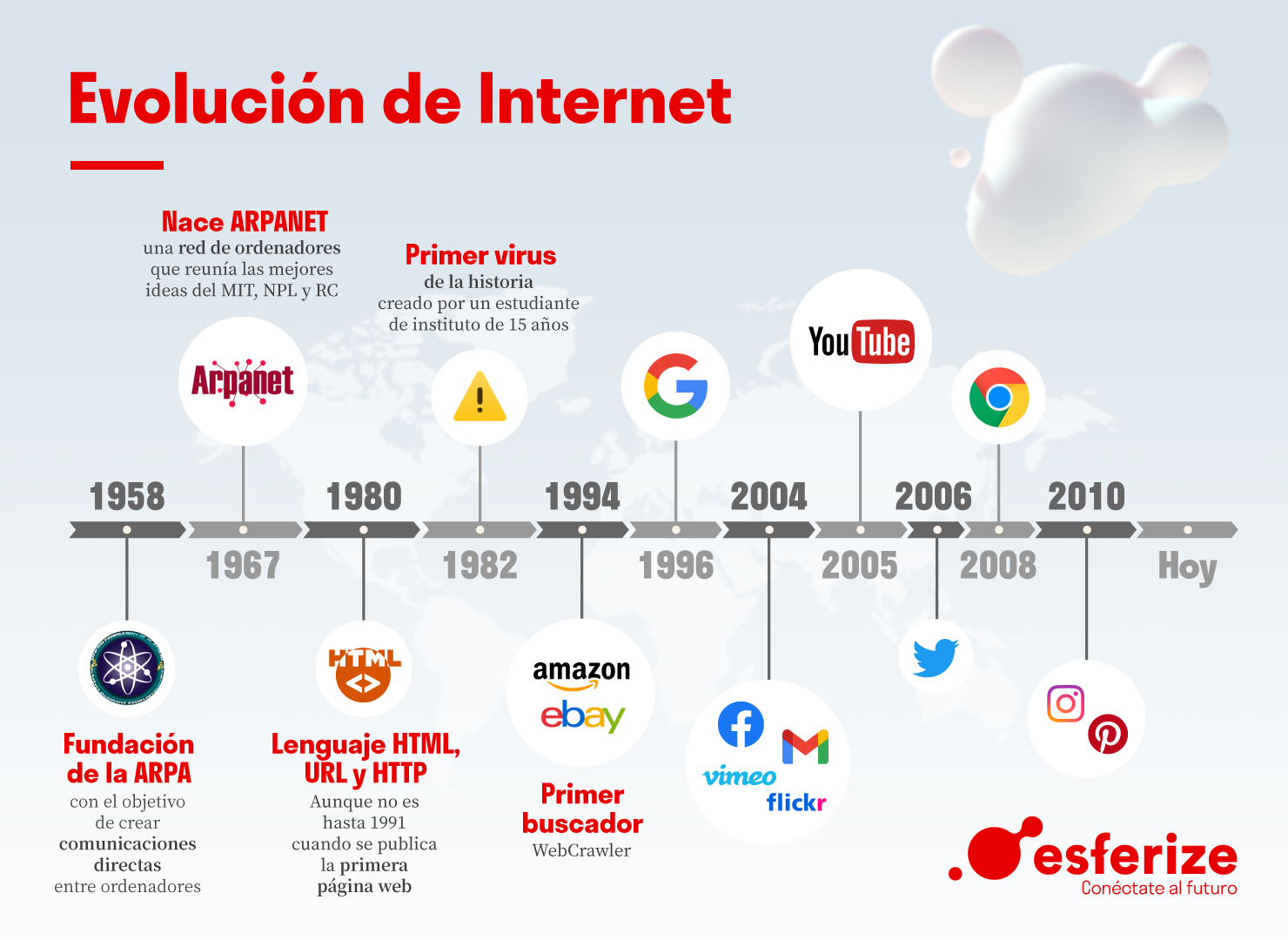
Internet: De la cuna a la hiperconectividad
La gran evolución del
internet
La herramienta que nació
como un proyecto militar
con el fin de mantener la
comunicación entre
diferentes puntos de
Estados Unidos, se ha
convertido en algo
fundamental en nuestro
día a día.
¿Quién se acuerda de la
vida antes de que este
fenómeno apareciera?
Y NO FUE HACE TANTO,
PUES SU NACIMIENTO
OFICIAL FUE EN 1969.
COLOMBIA SE CONECTA A INTERNET, EL 4 DE JUNIO DE 1994; POR MEDIO DE UNA
SEÑAL QUE UTILIZA IMPSAT SE
REDIRECCIONA DESDE LA TORRE
COLPATRIA Y LLEGA A UNIANDES. A PARTIR
DE ESTE AÑO SE ORGANIZA EL PANORAMA
PARA EL DESARROLLO DE LA INTERNET.
Primera conexión
LA PRIMERA CONEXIÓN FUE
ENTRE LOS ORDENADORES DE
STANDFORD Y UCLA, MOMENTO
EN EL QUE TAMBIÉN NACIÓ
ARPA .
Poco después de este
acontecimiento se podían
numerar con los dedos de
una mano las
universidades conectadas.
1-Red que acabó denominándose
ARPANET y su objetivo era
mantener estas comunicaciones
en caso de guerra.
2-No fue hasta 1970 cuando
ARPANET se consolidó del todo.
Momento en el que Roy Tomlinson
envió su primer email.
3-Aparece el virus llamado
Creeper.
como en toda historia importante, siempre hay
varias fechas señaladas. En los 80 el número de
ordenadores fue aumentando y su demanda
creciendo a la par
1-1982 empieza a producirse una
mejora de sus capacidades con la
creación de los emoticonos.
2-1989, Tim Bernes Lee, describió el
protocolo de transferencia de
hipertextos dando lugar a la
primera web a través de 3 nuevos
recursos: HTTP, HTML y Web
Browser.
3-1991 los usuarios externospudieron acceder a estainformación. Desde entonces elmundo digital empezó a crecer a unritmo agigantado.
www
World Wide Web que en tan solo cuatro
años pasó de 100 World Wide Sites a más
de 200.000.
1-En 1994 se funda Yahoo! y
justo al año siguiente
Microsoft lanza Internet
Explorer
2-1998 nace Google
3-2001 se conoce como el
nacimiento de Wikipedia, la
enciclopedia digital.
2003 y 2005
Se generan varios hitos en la
evolución de internet gracias a la
aparición de diferentes
plataformas.
De la web estática a la web
ubicua: ¿qué es y cómo
hemos llegado a la Web 4.0?
La Web 1.0 es la original, el
principio, el primer contacto que
tuvimos con un entramado de
páginas web, en las que
básicamente nos limitábamos a
consumir contenido sin más
actualización o interacción.
La Web 2.0, por su parte, fue la
primera gran evolución. La
conocida web social nos ha
permitido intercambiar
información entre usuarios a
través de blogs o las populares
redes sociales que hoy usan
millones de usuarios en todo el
mundo.
La Web 3.0 o web semántica es un salto
tecnológico desde esa versión 2.0. En la Web 3.0,
la clave y principal factor diferencial es el cómo
accedemos a la información. Aquí los buscadores
son clave pero no por sus mejores algoritmos,
mayor indexación de información u otros extras,
lo son porque permiten hacer uso de un lenguaje
más natural, de forma que obtenemos una web
(información) más personalizada, descartando
información que para cada uno de nosotros será
irrelevante.
La Web 4.0 es el próximo gran avance y se centra
en ofrecer un comportamiento más inteligente,
más predictivo, demodo que podamos con sólo
realizar una afirmación poner en marca un
conjunto de acciones que tendrán como
resultando aquello que pedimos o decimos.
¿PARA QUÉ SIRVE LA WEB 4.0?
Esta nueva versión de la red se basa en explotar toda la
información que ahora mismo contiene, pero de una forma
más natural y efectiva.
Un nivel de interacción más completo y personalizado. Es
decir, puedes decirle «Reserva una mesa para cenar hoy» o
«Pide un taxi» a tu dispositivo -que puede ser un smartphone,
wearable o quién sabe cuál- y automáticamente ejecuta dicha
acción sin más intervención propia.
Estas son sus funcionalidades:
Ofrece soluciones a partir de toda la información que existe
en la web.Para lograrlo, se fundamenta en cuatro pilares.
La comprensión del lenguaje natural y tecnologías Speech to
text (de voz a texto y viceversa).
Nuevos sistemas de comunicación máquina a máquina
(M2M).
Uso de la información de contexto. Por ejemplo, ubicación
que aporta el GPS, ritmo cardiaco que tu smartwatch registra,
etc.
Nuevo modelo de interacción con el usuario.
¿Cómo llegamos a
la Web 4.0.?
Gracias a la propia evolución de la tecnología. Empresas
como Google, Microsoft o Facebook, entre otras, están
desarrollando nuevos sistemas que gracias al Deep Learning
y Machine Learning serán capaces de procesar información
de forma similar a como lo haría el cerebro humano.
¿Machine Learning?
Es una disciplina del campo de la Inteligencia Artificial que, a través
de algoritmos, dota a los ordenadores de la capacidad de identificar
patrones en datos masivos y elaborar predicciones (análisis
predictivo). Este aprendizaje permite a los computadores realizar
tareas específicas de forma autónoma, es decir, sin necesidad de ser
programados.
Aprendizaje
supervisado:
Estos algoritmos cuentan con un aprendizaje previo basado en un
sistema de etiquetas asociadas a unos datos que les permiten tomar
decisiones o hacer predicciones. Un ejemplo es un detector de spam
que etiqueta un e-mail como spam o no dependiendo de los patrones
que ha aprendido del histórico de correos (remitente, relación
texto/imágenes, palabras clave en el asunto, etc.).
Aprendizaje no
supervisado:
Estos algoritmos no cuentan con un conocimiento previo. Se
enfrentan al caos de datos con el objetivo de encontrar patrones que
permitan organizarlos de alguna manera. Por ejemplo, en el campo
del marketing se utilizan para extraer patrones de datos masivos
provenientes de las redes sociales y crear campañas de publicidad
altamente segmentadas.
Aprendizaje por
refuerzo:
Su objetivo es que un algoritmo aprenda a partir de la propia
experiencia. Esto es, que sea capaz de tomar la mejor decisión ante
diferentes situaciones de acuerdo a un proceso de prueba y error en
el que se recompensan las decisiones correctas. En la actualidad se
está utilizando para posibilitar el reconocimiento facial, hacer
diagnósticos médicos o clasificar secuencias de ADN
¿Qué es deep
learning?
Deep learning es un subconjunto de machine learning (que a su vez es
parte de la inteligencia artificial) donde las redes neuronales,
algoritmos inspirados en cómo funciona el cerebro humano,
aprenden de grandes cantidades de datos.
Los algoritmos de deep learning realizan una tarea repetitiva que
ayuda a mejorar de manera gradual el resultado a través de ‘’deep
layers’’ lo que permite el aprendizaje progresivo. Este proceso forma
parte de una familia más amplia de métodos de machine learning
basados en redes neuronales.
Los algoritmos de deep learning realizan una tarea repetitiva que
ayuda a mejorar de manera gradual el resultado a través de ‘’deep
layers’’ lo que permite el aprendizaje progresivo. Este proceso forma
parte de una familia más amplia de métodos de machine learning
basados en redes neuronales.
Características
de deep learning
Asistente de experimentos
Inicie y supervise los experimentos de entrenamiento por lotes y luego
compare el rendimiento entre modelos en tiempo real sin preocuparse
por las transferencias de registro y los scripts para visualizar los
resultados
Cómputo de GPU elástico
Capacite redes neuronales en paralelo, utilizando las GPU K80, P100 y V100 de
NVIDIA Tesla, que son líderes del mercado. Pague sólo por lo que utiliza. Con la
asignación automática, no tiene que acordarse de cerrar sus instancias de
capacitación en la nube. No hay clústeres o contenedores para administrar
Beneficios de
deep learning
Ahorre tiempo, y no solo dinero
Utilice su IDE preferido y sus flujos de trabajo existentes. La CLI, la biblioteca
Python y el acceso REST están equilibrados mediante herramientas de
depuración visual. Diseñe y optimice sus redes mejor y más rápido.
Inteligencia bajo demanda
El entrenamiento gestionado implica que usted se puede enfocar en el diseño
de estructuras de red neuronales óptimas. Los activos de entrenamiento se
almacenan para usted. La asignación automática significa que sólo paga por los
recursos de cálculo necesarios para el trabajo.
Infraestructura de nube confiable
Optimizado para entornos de producción empresarial, se ejecuta en la misma
infraestructura que hospeda los servicios cognitivos de IBM Watson.
Colaboración en equipo
Comparta experiencias, depure arquitecturas neuronales, acceda a datos
comunes en bibliotecas alojadas y entregue modelos versionados a su equipo
para ayudar a alimentar un flujo continuo de aprendizaje con datos.
Comentarios
Publicar un comentario